
|
| B+Tree Guide |
| Home | B+Tree Product | B+Tree Guide | B+Tree Performance | Demos | Licensing and Pricing | B+Tree FAQ |

|
The theory of BTrees
What is a BTree?
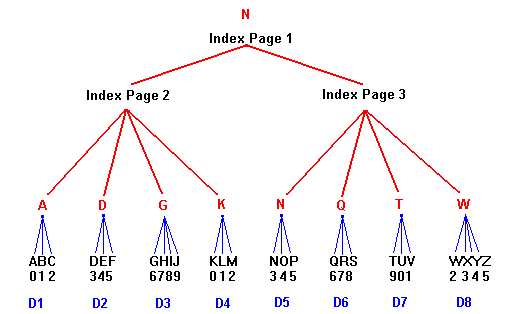
B-Trees are highly efficient data storage systems used by a number of operating systems and languages e.g. Novell, MUMPS. They provide rapid access to stored data using textual keys. The B-Tree presented here is in fact a B+Tree - this is distinguished from other B-Trees by its use of two files - one holds the indices and the other holds the indices and data. The index file is much smaller than the combined total of all the indices since it holds only the first index to each page in the index file. In simplified form the B+Tree looks like this -
As the diagram shows we only need 9 keys to access the 26 pieces of data. In fact a data page can hold much more than the amount of data we have shown in this trivial example. We can also see that to find out which data page holds a particular piece of data we only need to look at 2 index pages (i.e. we only have to access the disk twice. Let's say we want the data held at index 'R'. We access the Root Index Page (this is always the first page accessed when looking up an index - In this case Index Page 1). 'R' is greater than 'N' so we look at index page 3 (I3). 'R' is greater than 'Q' but less than 'T' so it must be in data page 6 (D6). We find then that the data corresponding to 'R' is 7. In practice very large quantities of data can be stored using only 3 or 4 index 'levels' and since the number of disk accesses is determined by the number of levels (i.e. 1 access is required per level) we can see that data retrieval can be very fast indeed. The number of levels is determined not only by the quantity of data stored in the file but also by the size of the keys used and the size of the data and index pages used. Very large keys in very small pages will result in an increased number of index pages and therefore in index 'levels'. There are two different types of level in the tree IndexPages 2 and 3 are said to be at the 'leaf' level in the tree - i.e. they contain pointers to data pages. Index page 1 is at the 'non-leaf' level and contains pointers to other index pages. Since the non-leaf levels are use primarily for navigation of the tree they have a different structure to the leaf levels. Non-leaf index pages always have one more page pointer than they have indices. This is because the indices are used comparatively. In our simple illustration above 'N' is the only index but we have two pointers - one to IndexPage 1 and another to IndexPage 2. If the index we wish to find is less than 'N' we go to IndexPage 1 , if it is greater than or equal to N we go to IndexPage 2. This reduces the number of keys required in each non-leaf index block. If there are n levels in a B+ Tree then there will always be 1 leaf level and n-1 non-leaf levels. Let us now look at a less trivial example. Say that we wish to store 2000 records with an index length of 25 and a data length of 50 e.g. a collection of names with addresses and phone numbers. If we set the data page size and the index page size to 512 bytes we end up with the following calculation (the overheads are required for the maintenance of the tree ) :- data+index - each is 75 + overhead ( 3) The penalty paid for this is the size of the files. In this case the size of the index file is 24 pages (including 1 control page) or 12k and the size of the data file is 335 pages (including 1 control page) or 167.5k - a total of 179k for 150000 bytes of data. Using 512 byte index pages and 4096 byte data pages you would end up with 40 data pages (160k) and 5 index pages (2.5k) and would only require 3 disk accesses per data fetch. The data levels are all held in one file (SOMENAME.DAT) and the index levels in another (SOMENAME.IND). Only three general operations are required to maintain a B+ tree database:-
Other specific operations are used to traverse the tree sequentially or to delete large amounts of data efficiently. Operations are also required to open and close the tree. What advantages are there to using a B+Tree?BTrees span the area between memory resident keyed collections such as HashMaps and full scale disk-based data storage mechanisms such as relational databases. They have the advantage of being disk persistent without needing the design and management overhead associated with databases. By cacheing the BTree pages performance can be in the same order as memory-based collections (See performance figures here). Databases tend to impose restrictions on data size and type and to be inefficient when they don't. They also tend to be inefficient to traverse - for example where you want to keep getting the next record or the previous record. Because B+Trees always keep their data in order traversal (especially where pages are cached) is always extremely fast. Because BTrees always maintain their order they don't tend to degrade as badly as databases (Virtual Machinery provides a toolkit which rejuvenate a degraded BTree). You can find out more about our implementation on the BTree FAQ page. The best way to find out more about or B+Trees is to download our sample applications here - these sample applications contain full code will show you how to make the most efficient use of B+Trees in your application. We always welcome feedback on our product and demos - please feel free to contact us using the link at the bottom of the page. Why should I use Virtual Machinery's BTree?Virtual Machinery have been producing BTree code since 1990 when they produced one of the first B+Trees to be written entirely in an object-oriented language (Smalltalk/V for DOS). The version for the Java platform has been in existence since 1997. Virtual Machinery's version is extremely efficient and when used in conjunction with caching can give performance figures for reads in the sub-millisecond region (See figures here). Virtual Machinery's BTree implementation also provides transaction control. Despite all this functionality the standard jar only has a footprint of 38k. We also provide a version for mobile devices including the J2ME Java Platform and the Apple iOS platform. The standard Java version works without modification on the Google Android (TM) Mobile platform. All our products come with full documentation and demonstration code which will get you up and running quickly. We also produce a toolkit which allows you to inspect and repair B+Trees created with our code. You can download demo code here.
|

|
|
||||